Legacy detection systems lack intelligence. And while LiDAR and Radar are considered modern technologies, they still fall short—offering limited classification, no scene understanding, and no reliable path to validation. When precision, safety, and adaptability are essential, only Currux Vision delivers the accuracy, transparency, and real-time learning today’s traffic environment demands.
What sets Currux Vision apart?
We outperform both traditional and modern sensors by using high-resolution RGB video and deep learning models trained and validated on the same video streams our system captures in the field—delivering insight, not just detection.
Here’s why that matters:
- Ground Truth Validation: Currux Vision encodes each object—vehicle, pedestrian, or cyclist—into rich visual embeddings that capture shape, motion, texture, and environmental context. This allows for precise, frame-by-frame ground truth verification against AI outputs. In contrast, Radar and LiDAR produce sparse point clouds or signal blobs with no appearance data, making accurate validation of object class, trajectory, or presence nearly impossible.
- Training at Scale: With dense pixel-level data, our models are trained on real-world conditions—urban geometry, lighting variations, occlusions, and weather—without relying on synthetic environments or manual stitching of low-fidelity data.
- Scene-Level Understanding: LiDAR provides 3D geometry but lacks color, texture, or environmental detail. Radar provides signal reflections with no object-level fidelity. Currux Vision embeds objects with a full multidimensional signature: shape, motion, color, context, and temporal behavior—enabling more accurate classification and prediction.
- Self-Improving AI: Our feedback loop allows intersections to improve over time. We can re-label edge cases, retrain models based on specific site characteristics, and deploy updates—all validated visually with the captured streams. This level of adaptive learning is not feasible with Radar or LiDAR alone.
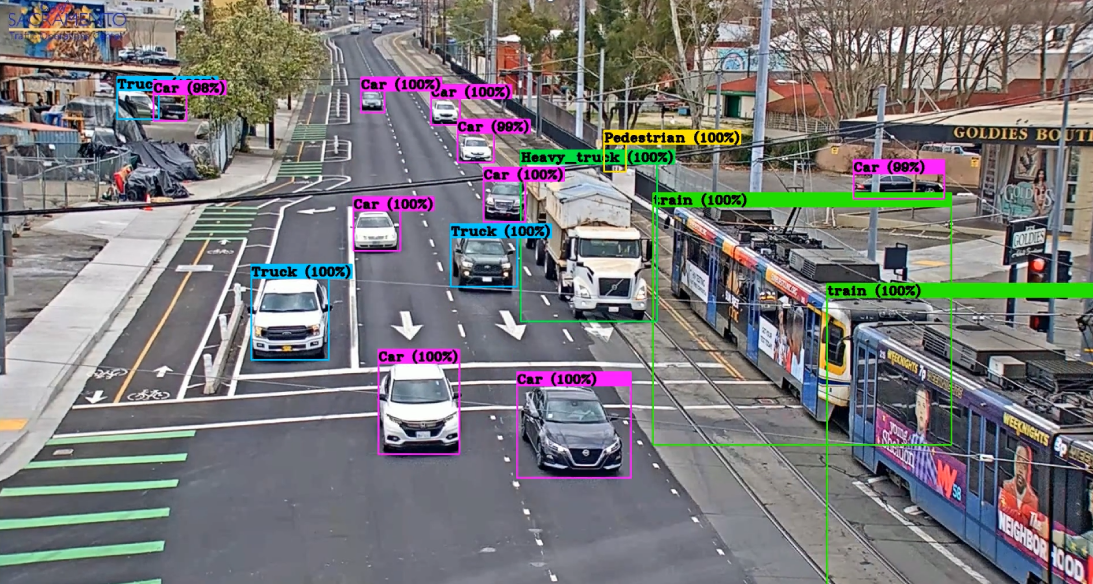
See real-world image examples below: The difference isn’t subtle.

Currux Vision doesn’t just detect—it understands. While other systems rely on sparse signals or simple motion cues, we generate rich object embeddings that drive deeper insights and smarter infrastructure.
TLDR: If you can't see it, you can't verify it—and you certainly can't train on it.
#CurruxVision #EdgeAI #TrafficDetection #AIValidation #ComputerVision #LiDAR #Radar #SmartCities #ITS #TransportationAI #UrbanMobility